When we talk about system performance in the context of concurrency, contention often takes center stage as one of the biggest bottlenecks.
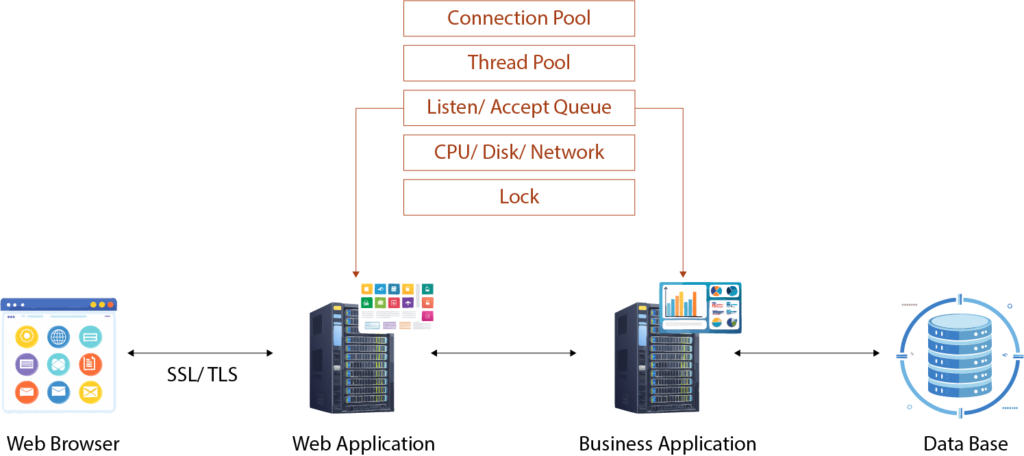
Contention occurs when multiple processes or threads compete for limited resources, whether it’s CPU, memory, disk, network bandwidth, or locks. Over time, I’ve learned to recognize and mitigate these bottlenecks by observing how they manifest in real-world systems.
In this post, we’ll break down system resource contention step by step, exploring where it arises and how it impacts performance. By understanding the underlying causes, you can better design systems to minimize latency and maximize throughput.
The Lifecycle of a Request: Where Contention Happens
Imagine a request arriving at a system—not the only request, but one of many competing for resources. The contention it faces depends on where it is in the processing pipeline. Let’s follow the journey of this request through a typical system and identify the key choke points.
1. The First Hurdle: Network-Level Contention
When a request first hits the server, it lands in a listen queue. If the server is overwhelmed (e.g., due to high traffic or backend slowness), the request may get stuck here.
If the listen queue isn’t the bottleneck, the request moves to the accept queue, where the server decides whether to process it. However, the size of these queues is finite. If the queues are full, new requests are rejected outright, and the client sees errors.
Here’s a real-world example: In a microservices-based architecture I worked on, a surge in traffic to one service caused the network queues to fill up. Even though downstream services had capacity, requests never made it past the gateway because the frontend servers were overwhelmed. We had to increase queue sizes and introduce rate limiting to handle spikes more gracefully.
2. CPU Contention: Threads Are Not Infinite
Once a request passes the network queues, it needs CPU time to process. But CPU time isn’t allocated directly to requests—it’s allocated to threads. Most server applications rely on a thread pool, where each thread processes one request.
If the thread pool is fully utilized, incoming requests must wait until a thread becomes available. This contention can significantly delay processing.
I’ve seen this firsthand in systems where thread pools were configured too small for peak loads. During busy periods, the queue for threads grew rapidly, adding latency and creating a snowball effect. Adjusting thread pool sizes dynamically based on workload metrics helped mitigate this issue.
3. Context Switching: Hidden Overhead
Even when threads are available, excessive context switching can slow things down. Context switching happens when a CPU shifts its focus from one thread to another, often because a thread is waiting for I/O or locks.
For example, in a data-processing pipeline, I noticed high latency due to threads frequently waiting for locks on shared resources. The CPU spent more time switching between threads than doing actual work, degrading throughput. Minimizing lock contention (more on that later) significantly reduced context switching overhead.
4. Backend Contention: Connection Pool Limits
Once a request is assigned a thread, it often needs to interact with a backend—be it a database, another service, or an external API. These backends have their own resource limits, often managed through connection pools.
If all connections in the pool are in use, threads must wait. This can lead to cascading delays, especially if the backend is slower than the rate at which requests arrive.
In one of my previous projects, a database connection pool became a major bottleneck during peak hours. Increasing the pool size temporarily alleviated the issue, but the real fix came from optimizing query performance and caching frequently accessed data to reduce the load on the database.
5. Disk Contention: The Serial Reality of I/O
Disk access is another frequent source of contention, particularly in systems that rely heavily on databases or file storage. Modern disks are fast, but they still operate more like a shared resource than parallel processors.
For instance, a system processing large datasets from disk often experiences contention as multiple threads compete for access. Even SSDs can become bottlenecks under heavy loads, though their performance is significantly better than traditional hard drives.
6. Network Contention: The Microservices Dilemma
In distributed systems, especially those built on microservices, internal network contention can arise. Services often need to make multiple calls to other services to fulfill a single request. If the internal network becomes saturated, even simple requests can experience significant latency.
In one architecture I worked on, a single request to the API gateway triggered calls to over 10 microservices. During high traffic, the internal network couldn’t keep up, resulting in timeouts and degraded user experience. Adding circuit breakers and consolidating service calls helped reduce the load on the network.
7. Lock Contention: The Serial Gatekeepers
Locks are perhaps the most notorious source of contention in concurrent systems. They exist to ensure consistency in shared resources but often become bottlenecks themselves.
For example, a shared in-memory cache might require locks to prevent data corruption. If multiple threads attempt to acquire the same lock simultaneously, they must wait their turn, creating delays. This is a classic example of how locks serialize access to resources, reducing concurrency and throughput.
In a high-traffic e-commerce application I worked on, lock contention on inventory data became a major issue during sales events. Moving to a lock-free data structure significantly improved performance, allowing more threads to access the data simultaneously.
Summary of Common Sources of Resource Contention
To summarize, here are the key resources where contention often arises:
- Network: Listen and accept queues, internal network saturation.
- CPU: Thread pool limits, context switching overhead.
- Disk: Limited parallelism in disk I/O, especially in database operations.
- Backends: Connection pool limits, slow external services.
- Locks: Serialized access to critical sections of code.



0 Comments