When building scalable systems, the first step is understanding how to scale up and scale out your architecture. Whether you’re building a microservices-based application or scaling a monolithic system, achieving scalability starts with a strong foundation in modularity. In this post, we’ll explore the importance of modularity in achieving system scalability, focusing on how it applies to your system’s key components:
- Web Application Layer
- Business Application Layer
- Database Management System (DBMS)
We’ll also discuss how horizontal scaling, vertical scaling, and service decoupling can help your system handle increased load while maintaining performance and reliability.
The Three (most common) Core Components of Scalable Systems
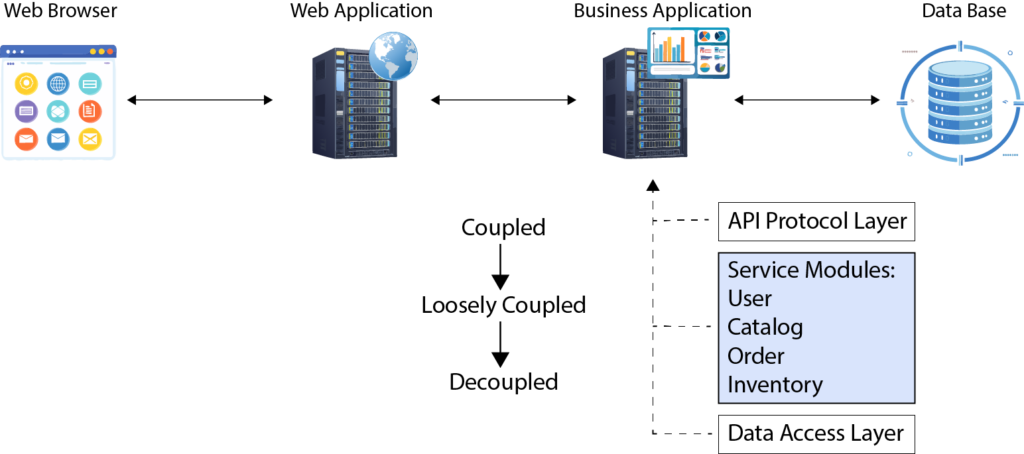
To scale your system, you need to examine its three main components:
- Web Application Layer (Frontend) – This is where user interaction happens. It handles incoming requests, processes them, and sends responses back to users. While it may contain some lightweight business logic, its primary focus is on UI/UX, input validation, and request handling.
- Business Application Layer (Backend) – This is the heart of your system, where the majority of your business logic resides. It processes data, enforces business rules, and handles transactions. This layer is often the most complex and the most critical for scalability.
- Database Management System (DBMS) – This is the foundation for data storage and retrieval. A poorly optimized DBMS can become a serious bottleneck as your system grows, making it crucial to implement effective database scaling strategies.
The Importance of Modularity in Business Logic
When building scalable systems, the most critical factor for long-term success is modularity in business logic. Modularity means designing your business logic in a way that different parts of the application are organized into self-contained, loosely coupled modules. This approach provides flexibility, improves scalability, and simplifies maintenance. Without modularity, systems become complex and fragile, making it nearly impossible to scale effectively.
Why Modularity is Essential for Scalable Architecture
1. Loosely Coupled Components for Maximum Flexibility
In a modular system, individual components can function independently. This loose coupling means changes made in one part of the system are less likely to break or affect other components. For example, in an e-commerce system, a change in the payment processing logic should not affect the inventory management system.
Loose coupling reduces the risk of cascading failures, which are common in monolithic applications. It also allows different teams to work on separate modules in parallel, increasing development speed and improving overall system stability.
2. Easier Maintenance and Faster Debugging
A modular architecture makes it significantly easier to maintain and debug your application. Each module is responsible for a specific piece of functionality, so when an issue arises, it can be isolated and resolved quickly without impacting other parts of the system.
For instance, if a bug exists in the user authentication module of an online service, a modular structure ensures that this issue won’t crash the order processing or notification services.
3. Reusability of Modules
One of the biggest advantages of modularity is reusability. Well-designed modules can be reused across multiple applications or different parts of the same system. For example, a user authentication module built for one application can be reused in another system with minimal changes.
Reusable modules reduce development time and ensure consistency across different services. This is especially valuable in large organizations where multiple teams work on related systems.
4. Simplifying the Transition to Microservices
If you’re starting with a monolithic architecture, writing modular business logic is a critical first step toward transitioning to a microservices architecture. Microservices are built around the principle of service-oriented architecture (SOA), where each service is a self-contained unit with its own database and business logic.
In a monolithic application, adopting a modular approach allows you to gradually decouple services and scale the system over time. For example, a monolithic customer management system can be divided into separate microservices for user registration, customer support, and order history.
5. Better Scalability and Load Distribution
Modular business logic enables horizontal scaling by distributing different modules across multiple servers or containers. When a specific module experiences high traffic, it can be scaled independently without affecting the rest of the application.
For instance, in a social media platform, the newsfeed service may experience significantly more load than the user settings module. By isolating these services into separate modules, you can scale the newsfeed module horizontally while keeping the rest of the system stable.
How to Achieve Modulatiry I Business Logic
We’ve covered the importance of modularity, let’s look at how to implement it effectively. Here are a few best practices for creating modular business logic:
1. Identify Core Business Functions and Group Them Into Modules
The first step is to break down your business logic into distinct modules based on core functionalities. Each module should focus on a single responsibility.
- User Module: Handles user registration, login, authentication, and profile management.
- Order Management Module: Manages order placement, order history, and order tracking.
- Inventory Module: Keeps track of available stock, restocking, and inventory history.
- Notification Module: Manages email and SMS notifications for events like order confirmations and account changes.
2. Implement a Layered Architecture
A layered architecture separates your business logic from the data access layer and API layer. This decoupling ensures that changes in the way your business logic accesses data or serves responses do not require changes to the business logic itself.
For example:
- The data access layer can handle interactions with multiple databases (SQL or NoSQL), and switching databases won’t affect the business logic.
- The API layer can evolve from REST to gRPC or GraphQL without modifying the core business logic.
3. Adopt Interface-Based Design
Using interfaces or abstractions helps achieve independence between modules. This makes it easier to change or replace modules without disrupting the system. For example, if you want to replace your caching mechanism from Redis to Memcached, an interface-based design ensures you only need to modify the implementation, not the business logic.
4. Avoid Circular Dependencies
Circular dependencies occur when two or more modules depend on each other directly or indirectly. This tight coupling can lead to system failures and make it difficult to scale. To prevent this, each module should have clear boundaries and rely on well-defined interfaces for communication.
5. Leverage Dependency Injection and Design Patterns
Using design patterns like Dependency Injection, Factory Pattern, and Repository Pattern can further decouple your business logic from external dependencies, improving testability and scalability.
Separating the API Protocol Layer and Data Access Layer
In a scalable architecture, one of the core principles is to separate the API protocol layer from the data access layer. This separation ensures that your system remains flexible, easier to maintain, and highly scalable. The goal is to allow changes in one layer without requiring modifications in the other, enabling your application to evolve rapidly while minimizing the risk of breaking core business logic.
When we talk about scalable systems, it’s critical to decouple these two layers because each layer serves a different purpose:
- The API protocol layer defines how external clients interact with your application.
- The data access layer handles interactions with underlying data sources, such as relational databases, NoSQL databases, or external APIs.
By separating these layers, you can achieve horizontal scalability, reduce dependencies, and increase code reusability across different parts of the system.
Why Separating API and Data Access Layers is Crucial for Scalability
1. Independent Evolution of the API and Data Models
When the API layer and the data access layer are decoupled, they can evolve independently. This means you can update the API to serve different clients (e.g., mobile apps, web apps, third-party services) without worrying about changes to your underlying data model.
For example:
- You may decide to expose a GraphQL API for new clients while keeping an existing REST API for legacy clients.
- Your data access layer can switch from SQL to NoSQL databases without affecting the API responses.
This flexibility is essential for systems that need to adapt quickly to changing business requirements and technology trends.
2. Easier Scalability and Performance Optimization
Separating the two layers allows each to scale independently based on demand. The API layer can handle thousands of concurrent requests by deploying additional API instances, while the data access layer can scale its databases or caching solutions without bottlenecks.
For example:
- In a high-traffic e-commerce application, you might scale the API layer horizontally by adding more web servers behind a load balancer.
- At the same time, you could optimize the data access layer by implementing database sharding or distributed caching.
This independent scalability ensures that each layer can be fine-tuned for performance without affecting the other.
3. Enhanced Maintainability and Code Organization
A well-structured separation between the API protocol layer and the data access layer makes your code easier to maintain and understand. Developers can focus on a specific layer without needing to know the intricacies of the other.
- The API layer can focus on request validation, response formatting, authentication, and routing.
- The data access layer can handle database queries, data transformations, and interaction with external services or caches.
This approach also makes onboarding new developers faster and more efficient, as they can specialize in one layer without being overwhelmed by the entire codebase.
4. Improved Testability
By isolating these two layers, you can test them independently. This results in more reliable and maintainable tests, reducing the likelihood of bugs.
For example:
- Unit tests for the API layer can focus on ensuring the correctness of request handling, input validation, and response generation.
- Integration tests for the data access layer can validate that queries are correctly executed, data is returned as expected, and error conditions are handled gracefully.
This modular testing approach makes your system more robust and scalable over time.
Practical Steps for Implementing Separation of Layers
1. Define Clear Boundaries and Responsibilities
The first step in separating the API and data access layers is to define clear boundaries for each layer.
- The API protocol layer should only handle tasks related to external communication, such as parsing requests, validating input, and generating responses.
- The data access layer should be responsible for interacting with data sources, handling caching, and managing connections to external systems.
2. Use Design Patterns and Abstractions
Design patterns like the Repository Pattern and Data Mapper Pattern help enforce separation between these layers. These patterns abstract the data access logic from the business logic, ensuring that the API layer only interacts with well-defined interfaces.
For instance:
- The Repository Pattern provides an abstraction for data operations, making it easier to switch between different data sources.
- The Data Mapper Pattern helps map data between the database schema and your application’s domain model, allowing the API to remain unaffected by changes in the data schema.
3. Implement Dependency Injection
Dependency Injection (DI) is a powerful technique for decoupling layers. It allows you to inject the required dependencies into your API layer at runtime, making it easier to swap out or modify the data access layer without changing the API layer’s code.
For example, you could inject a MySQLRepository or MongoDBRepository into the API controller based on the configuration, enabling seamless transitions between different databases.
4. Introduce a Service Layer
In more complex systems, introducing a service layer between the API layer and the data access layer can provide additional flexibility and abstraction. The service layer acts as an intermediary, coordinating business logic and managing interactions between the layers.
- API Layer → Service Layer → Data Access Layer
- The service layer encapsulates business logic and orchestrates data access, making it easier to implement cross-cutting concerns like caching, logging, and authorization.
Takeaway: Modular Code for Scalability
If you’re starting to build a system, make modularity your top priority. Modular code lays the foundation for future scalability and flexibility. Here’s a quick checklist to ensure you’re on the right path:
- Break Business Logic into Separate Modules: Identify distinct functions and create loosely coupled modules.
- Decouple API and Data Access Layers: Ensure your business logic is not tightly tied to specific protocols or databases.
- Plan for Horizontal Scaling: Design your architecture with horizontal scalability in mind, leveraging cloud services and load balancers to handle increased traffic.
By following these principles, you’ll create a system that’s easy to scale, maintain, and adapt to future demands.


0 Comments