While serial performance sets the foundation for individual request handling, real-world systems rarely deal with just one request at a time. As systems scale, concurrency-related latency becomes a critical factor in performance. Concurrency refers to a system’s ability to handle multiple requests simultaneously, leveraging parallelism to maximize throughput. However, as concurrency increases, so does the complexity of managing shared resources, leading to potential bottlenecks, contention, and queuing delays that can degrade overall responsiveness.
In this part of the blog, we’ll explore how concurrency-related latency emerges, its impact on system performance, and strategies for mitigation. From thread contention and resource locking to queuing dynamics and load balancing, understanding these elements will help you design systems that scale efficiently without compromising latency. Whether you’re building a cloud-native microservices architecture or a monolithic application, mastering concurrency-related latency is essential to delivering high-performance systems under heavy workloads.
Understanding Concurrency in Modern Systems
When we talk about optimizing system architecture, concurrency is an unavoidable topic. After you’ve addressed serial latency—let’s assume you’ve tuned those single-request latencies to their bare minimum—the next big lever to pull for performance is concurrency.
Concurrency is not just about doing things simultaneously; it’s about how well your system can coordinate tasks to achieve higher throughput. This is where things get exciting—and challenging.
What Concurrent Processing Is
Let’s start by defining it in practical terms. Imagine you have three requests that need to be processed. If you handle them one after the other, that’s a serial process. Simple and straightforward, but not always efficient.
Now, if your system can process those three requests at the same time, that’s parallel processing—what we dream of in a perfectly concurrent system. But reality is rarely that clean. Systems are often a mix of serial and parallel workflows. Parts of the process run concurrently, while others are bottlenecked by dependencies, resource contention, or synchronization needs.
Here’s an analogy: Think of a factory assembly line. Some parts of the line might allow multiple workers to assemble components simultaneously, while other steps—like a final quality check—might require items to pass through sequentially. Your code behaves in much the same way, transitioning between parallel and serial phases depending on its design.
Serial vs. Parallel Execution: A Closer Look
To understand concurrency-related latency, we must first dissect the performance characteristics of serial and parallel systems.
Serial Processing
In a serial system, throughput remains constant regardless of workload. For example:
- Scenario:
In a serial system, the processing rate doesn’t change regardless of how many requests or threads you throw at it. If one processor can handle one request per second, then three requests will take three seconds—no surprises there. Adding more processors doesn’t help because tasks are bottlenecked by the serial nature of the process. - Result:
Three requests take three seconds. Adding more processors won’t help because tasks are bottlenecked by serial execution.
Picture a single-lane road: no matter how many cars want to pass, only one car can proceed at a time. Adding lanes won’t help unless you redesign the road.
Parallel Processing
In an ideal parallel system, throughput scales linearly with resources:
- Scenario:
In an ideal parallel system, adding more processors or threads should increase throughput linearly. If one processor can handle one request per second, two processors should handle two requests per second, and so on. This is the dream scenario, and the performance graph for such a system would be a perfect straight line.
However, real-world systems are never fully parallel. They typically have serial portions—parts of the workflow that require synchronization, locking, or other mechanisms that enforce sequential execution.
The Reality: Mixed Processing
Most systems fall somewhere between serial and parallel. Let’s consider an example:
You have a multi-threaded Java application. Parts of the code execute independently, allowing requests to be processed concurrently. But when threads need to access shared resources (like a database record or file), they hit synchronized blocks or locks, temporarily forcing sequential execution. These serial portions act as roadblocks, limiting the overall throughput.
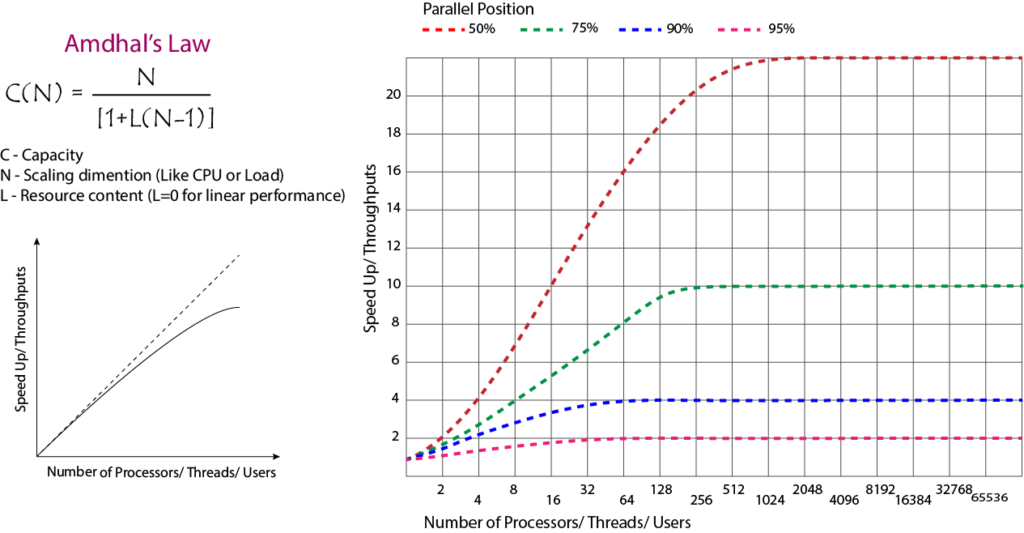
Now, here’s the important part: even a small percentage of serial processing can dramatically impact scalability. This is where Amdahl’s Law comes into play.
Amdahl’s Law in Action
Amdahl’s Law quantifies the theoretical speedup from parallelization, given the fraction of serial processing. Here’s how it plays out:
- 95% Parallel, 5% Serial:
- Scales well initially, but gains diminish as processors increase.
- Example: A web server with efficient threading but occasional database locks.
- 90% Parallel, 10% Serial:
- Throughput plateaus sooner, with lower overall gains.
- Example: A microservices architecture with frequent inter-service API calls.
- 75% Parallel, 25% Serial:
- Performance degrades rapidly; adding processors yields minimal benefits.
- Example: A legacy system with monolithic code and heavy synchronization.
- 50% Parallel, 50% Serial:
- Behaves like a fully serial system; scaling is futile.
Key Insight: Even a 5% serial component can cap scalability. Reducing serial bottlenecks is critical for high-concurrency systems.
Why Serial Portions Exist
Serial portions in a system are often unavoidable. They’re introduced when:
- Locks are required to ensure consistency (e.g., accessing shared resources like databases or files).
- Critical sections in code need to execute sequentially to maintain correctness.
- Resource contention forces processes to wait (e.g., queueing for a limited resource).
These bottlenecks might be caused by:
- Database locks during transactions.
- Synchronized blocks in your application code.
- Thread coordination overhead.
While we can’t eliminate these entirely, the goal is to minimize their impact.
Strategies to Mitigate Concurrency-Related Latency
Optimizing concurrency requires a mix of architectural design, code-level tweaks, and modern tooling. Below are battle-tested strategies to reduce serial bottlenecks.
1. Reduce Lock Contention
- Fine-Grained Locking: Replace coarse locks (e.g., entire database tables) with row-level or key-based locks.
- Lock-Free Data Structures: Use atomic operations or libraries like Java’s
ConcurrentHashMapor C#’sConcurrenDictionary<TKey, TValue>. - Time-Bound Locks: Implement timeouts to prevent indefinite blocking.
2. Embrace Non-Blocking Operations
- Asynchronous Programming: Use frameworks like Python’s
asyncioor Node.js’s event loop to avoid thread blocking. - Reactive Programming: Adopt reactive streams (e.g., Project Reactor) for high-throughput data processing.
3. Workload Partitioning and Sharding
- Horizontal Partitioning: Distribute data across shards to reduce database contention.
- Vertical Partitioning: Separate read/write workloads to dedicated servers.
4. Leverage Modern Concurrency Frameworks
- Java’s ForkJoinPool: Optimize divide-and-conquer tasks with work-stealing algorithms.
- Go’s Goroutines: Lightweight threads managed by the Go runtime for massive concurrency.
- Kubernetes Pod Autoscaling: Dynamically scale microservices based on load.
5. Optimize Resource Allocation
- Thread Pool Tuning: Adjust pool sizes based on workload (I/O-bound vs. CPU-bound).
- Connection Pooling: Reuse database connections to avoid setup overhead.
Conclusion: Balancing Concurrency and Correctness
Concurrency is both an art and a science. It’s about designing your system to handle tasks in parallel wherever possible while carefully managing the inevitable serial portions. Even a small serial component can severely limit scalability, so every percentage point matters.
By minimizing serial bottlenecks, leveraging modern frameworks, and continuously monitoring performance, you can build systems that scale gracefully under load. Remember:
- Every percentage of serial processing matters—even small optimizations yield outsized gains.
- Measure relentlessly: Use APM tools to identify hidden bottlenecks.
- Design for failure: Implement retries, circuit breakers, and backpressure mechanisms.
In the next part of this series, we’ll explore advanced techniques like data parallelism, actor models, and event sourcing to tackle concurrency at scale.



0 Comments