Understanding Serial Performance: The Foundation of System Responsiveness
When designing or analyzing a system’s performance, understanding serial request latencies is foundational.
Serial performance refers to the time a single request takes to traverse the system, moving step by step through various components like APIs, databases, and downstream services. This linear journey defines the baseline responsiveness of your application and directly impacts user experience. Whether you’re building a low-latency trading platform or a high-traffic e-commerce site, the efficiency of each serial interaction sets the tone for how well your system scales and responds under load.
In this blog, we’ll explore the key elements of serial performance, focusing on how latency accumulates at different stages and the factors that influence it. From network hops and database queries to processing delays and queuing effects, we’ll break down the individual contributors to serial latency. By understanding these elements, you can identify the choke points in your architecture and optimize them to ensure a fast, seamless experience for your users.
CPU Processing Latency
When diving into serial performance, one of the most critical aspects to address is CPU processing latency. This latency directly affects how quickly a request is processed and often boils down to two key factors: inefficient algorithms and context switching.
While inefficient algorithms are relatively straightforward to diagnose and optimize—think of refining computational complexity or reducing unnecessary loops—context switching is a subtler but equally significant issue. It’s not always immediately apparent but can significantly degrade system performance, especially in multi-threaded or multi-process environments.
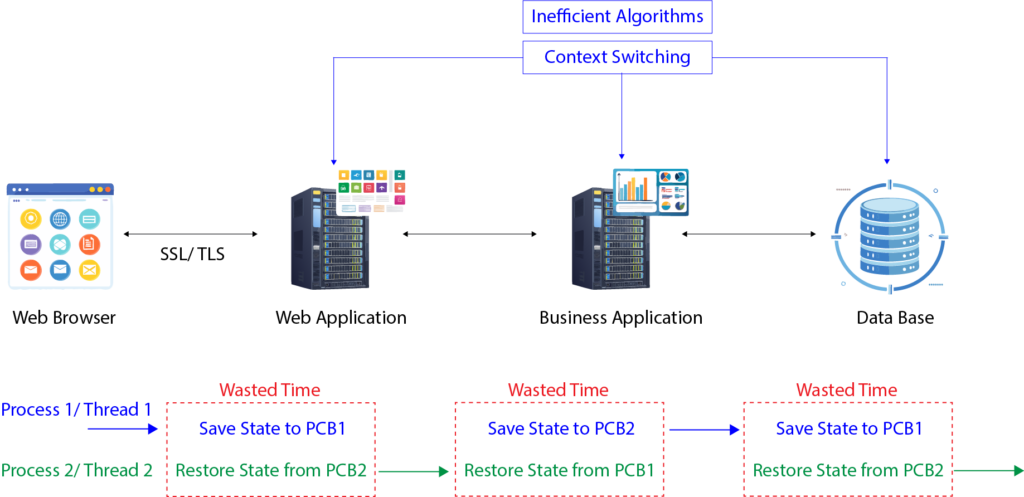
What Exactly Is Context Switching, and Why Does It Matter
Imagine a single-CPU machine running two processes, Process 1 and Process 2. At any given moment, the CPU can execute only one process, so the other must wait its turn.
Now, consider Process 1 is executing but needs to perform an I/O operation, such as accessing disk storage or making a network call. During this I/O operation, the CPU becomes idle for Process 1, so the operating system steps in to switch context, removing Process 1 from the CPU and loading Process 2 to utilize the idle CPU time. This process involves saving the state of Process 1 (its process control block) into memory and then restoring the state of Process 2 to begin its execution.
While this sounds efficient in theory, the act of context switching introduces latency. The CPU spends time-saving and restoring process states rather than executing actual tasks. For example, if Process 1 would normally complete its workload in 100 milliseconds, a few context switches could easily double this time to 200 milliseconds. Multiply this inefficiency across hundreds or thousands of processes or threads, and you can see how quickly it scales into a system-wide performance bottleneck.
Real-Life Implications of Context Switching
In modern systems, where multi-threading is the norm, the problem compounds further. Context switching isn’t limited to inter-process transitions—it occurs within threads of a single process too. For example, a web server handling concurrent requests may experience frequent context switches as threads block on I/O or compete for CPU resources. The cost of these switches can manifest as increased latency for individual requests, lower throughput, and, in extreme cases, system instability under high load.
Context switching also doesn’t happen in isolation. It interacts with other factors like CPU cache invalidation. When a process is swapped out, its cached data may no longer be relevant when it resumes execution, leading to additional delays as the cache is repopulated. These cascading effects make understanding and minimizing context-switching an essential skill for system architects and engineers.
Strategies to Minimize Context Switching
So how do we mitigate this issue? Here are some practical strategies:
- Reduce Avoidable I/O Operations:
- Use asynchronous I/O operations to keep processes from blocking unnecessarily.
- Batch small I/O operations into larger chunks to reduce the frequency of context switches.
- Optimize disk and network interactions to minimize wait times.
- Optimize Thread and Process Management:
- Over-provisioning threads may lead to excessive context switching, so tune thread pools for optimal utilization.
- Use CPU affinity—binding processes to specific CPU cores—to reduce the overhead of context switching.
- Leverage Profiling Tools:
- Tools like perf (Linux) or Process Monitor (Windows) can help pinpoint where excessive context switching is occurring. These insights can guide decisions on code refactoring, resource allocation, or even re-architecting bottlenecked components.
In summary, context switching is a hidden cost of multitasking that can erode performance if left unchecked. By understanding its impact and applying practical mitigation strategies, you can significantly reduce CPU latency and enhance overall system responsiveness.
Addressing CPU Processing Latency
When it comes to CPU processing latency, there are several practical approaches to optimize performance, many of which I’ve employed in real-world scenarios. These techniques primarily address two culprits: inefficient algorithms and context switching. While algorithms are often the first place we look for improvements—fine-tuning computational efficiency, reducing complexity, or optimizing database queries—context switching can be a hidden performance drain. Tackling it requires not just an understanding of system behavior but also deliberate architectural choices.

Optimizing CPU Usage by Reducing Context Switching
One way to mitigate context switching is by leveraging batch I/O operations. Imagine a scenario where your application makes frequent database calls to retrieve or write small chunks of data. Every call forces your process or thread to yield the CPU, triggering a context switch. By batching these operations—consolidating multiple reads or writes into a single transaction—you minimize both network overhead and CPU latency. This technique is particularly effective for logging, where instead of writing each log entry synchronously, you can aggregate them and write asynchronously in batches.
Speaking of asynchronous I/O, it’s a game-changer for applications with significant I/O operations. For instance, when logging, instead of blocking your main thread to write to a log file, delegate that task to an asynchronous worker thread. The main thread can continue processing requests, while the worker handles I/O in the background. Even if the worker thread experiences context switching, it doesn’t impact the primary flow of your application. This approach, which I’ve implemented in logging-heavy systems, dramatically reduces performance bottlenecks.
The Power of Single-Threaded Models
In high-load systems with frequent I/O operations, adopting a single-threaded model with asynchronous delegation can be highly effective. This design, exemplified by technologies like Node.js or Nginx, ensures that a single thread handles all incoming requests while delegating I/O tasks to auxiliary threads or event loops. The beauty of this model lies in its simplicity: the main thread remains glued to the CPU, never relinquishing control. Requests are processed sequentially or through non-blocking callbacks, keeping the CPU constantly engaged without the churn of thread switching.
For instance, consider a web server processing hundreds of simultaneous HTTP requests. Using a single-threaded model, the main thread parses and processes each request while offloading database or network calls to asynchronous handlers. Once these handlers complete, results are passed back to the main thread for final processing. This approach minimizes the overhead of managing multiple threads, which can quickly spiral into inefficiency under high loads.
Right-Sizing Thread Pools
Thread pools are another area where careful tuning can yield substantial gains. Too many threads competing for limited CPU resources can result in a “thread thrashing” scenario, where more time is spent switching between threads than doing actual work. For example, on a machine with two CPU cores, running 100 threads will almost certainly cause performance degradation. By experimenting with different pool sizes and profiling your application, you can identify an optimal configuration—one that balances concurrency without overwhelming the system.
Using Virtual Environments for Process Isolation
In multi-process environments, processes can compete for CPU resources, leading to starvation for some processes if one hogs the CPU. To mitigate this, consider running each process in its own virtual environment or container. Tools like Docker allow you to allocate specific CPU and memory quotas to each container, ensuring fair distribution of resources. This is particularly valuable when dealing with performance-sensitive applications on shared infrastructure.
Conclusion
Addressing CPU processing latency requires a combination of strategies that reduce inefficiencies and manage resource contention. From batching I/O and employing asynchronous operations to leveraging single-threaded models and optimizing thread pools, each decision can have a cascading impact on your system’s performance. Virtual environments provide an additional layer of control, ensuring that processes don’t interfere with each other. These are not just theoretical solutions; they are battle-tested approaches I’ve applied in production systems facing real-world constraints. By adopting these practices, you can unlock significant gains in CPU efficiency and system performance.



0 Comments