Caching is a powerful tool for boosting system performance and reducing latency, but it comes with its own set of challenges. While it can significantly reduce database load and improve user experience, managing a cache effectively requires careful planning and trade-offs. In this post, I’ll share insights on caching strategies from my experience, focusing on two critical challenges: limited cache space and cache invalidation (or inconsistency).
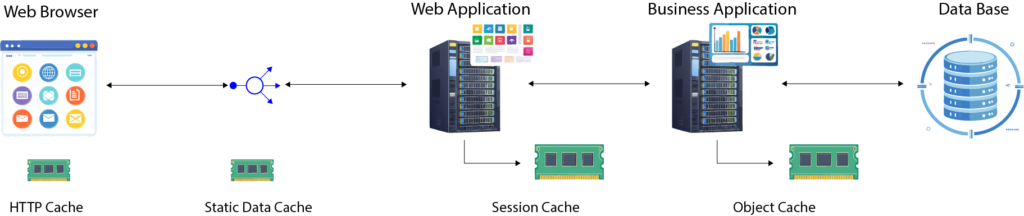
What Makes a Cache Effective
To tackle caching challenges, we first need to understand what makes a cache truly effective. The core metric is the cache hit ratio, which measures how often requests are served from the cache:
Cache Hit Ratio= Cache Hits / (Cache Hits + Cache Miss)
- Cache hit: When the cache serves a request directly, bypassing the database or API.
- Cache miss: When the requested data isn’t in the cache and must be fetched from the source.
A high cache hit ratio translates to faster responses and reduced load on the origin. This leads to a noticeable improvement in system performance, especially for applications with heavy read operations. But achieving that high hit ratio comes with its own set of obstacles, which we’ll explore next.
Challenge 1: Limited Cache Space
Memory is expensive, and cache storage is limited. Unlike disk storage, you can’t just add more memory endlessly without significant cost. This constraint forces us to carefully choose what data gets cached. In my experience, two primary factors drive this decision:
- Data Access Frequency: Frequently accessed data should always be prioritized for caching.
- Data Volatility: Data that rarely changes is a better candidate for caching, as it minimizes the risk of serving stale data.
Example: Selecting Cache Candidates
Imagine an e-commerce platform:
- Fast-moving items: These products are frequently viewed and sold but rarely updated. Perfect for caching.
- Slow-moving items: These are rarely accessed, even though their data doesn’t change often. Caching them wastes valuable space.
Data size is another critical consideration. Small objects are often more cache-friendly than large ones. For example, caching 10 small items may offer a greater performance boost than caching 3 large ones, depending on the access patterns. Balancing data access patterns and cache size is an ongoing challenge that requires continuous monitoring and adjustment.
Challenge 2: Cache Invalidation (Stale Data)
Cache invalidation is one of the hardest problems in system architecture. Cached data can easily become outdated if the underlying source data changes. Until the cache is updated or invalidated, it holds stale data, leading to inconsistencies that can confuse users and cause errors. I’ve found two primary strategies for dealing with this:
- Synchronous Update or Deletion
This approach updates or removes the cache entry whenever the source data changes. While it minimizes the window for inconsistencies, it requires reliable synchronization between the cache and database, which can be complex. - Time-to-Live (TTL)
With TTL, you set an expiration time for cached data. Once the TTL expires, the data is fetched again from the source. This works well for public caches and distributed systems, but it involves trade-offs:- High TTL: Reduces cache misses but increases the risk of serving stale data.
- Low TTL: Improves data freshness but increases the load on the origin.
Finding the right TTL requires experimentation, real-time monitoring, and frequent adjustments based on system behavior.
Practical Example: Optimistic Locking for Cache Updates
One way to manage cache consistency is through optimistic locking, which ensures updates occur only when the underlying data remains unchanged. This approach helps prevent race conditions and concurrent modifications, especially in distributed systems. Here are some practical examples in C# and Python.
C# Example: Optimistic Locking
using System;
using System.Collections.Concurrent;
public class CacheExample
{
private static readonly ConcurrentDictionary<string, (string Value, int Version)> Cache = new();
public static void UpdateCache(string key, string newValue, int expectedVersion)
{
if (Cache.TryGetValue(key, out var currentData))
{
if (currentData.Version == expectedVersion)
{
Cache[key] = (newValue, expectedVersion + 1);
Console.WriteLine($"Cache updated for key {key}");
}
else
{
Console.WriteLine($"Version mismatch for key {key}, update skipped.");
}
}
else
{
Cache[key] = (newValue, 1);
Console.WriteLine($"Cache entry created for key {key}");
}
}
public static void Main()
{
UpdateCache("item1", "value1", 0);
UpdateCache("item1", "value2", 1); // Successful update
UpdateCache("item1", "value3", 1); // Version mismatch
}
}Python Example: Optimistic Locking
from threading import Lock
class Cache:
def __init__(self):
self.cache = {}
self.lock = Lock()
def update_cache(self, key, new_value, expected_version):
with self.lock:
current_data = self.cache.get(key)
if current_data:
value, version = current_data
if version == expected_version:
self.cache[key] = (new_value, version + 1)
print(f"Cache updated for key {key}")
else:
print(f"Version mismatch for key {key}, update skipped.")
else:
self.cache[key] = (new_value, 1)
print(f"Cache entry created for key {key}")
# Example Usage
cache = Cache()
cache.update_cache("item1", "value1", 0)
cache.update_cache("item1", "value2", 1) # Successful update
cache.update_cache("item1", "value3", 1) # Version mismatchWrapping Up
Caching is an essential component of building high-performance systems, offering significant benefits in reducing latency and alleviating database or API load. However, these advantages come with inherent challenges, such as limited cache space and the complexity of cache invalidation. The effectiveness of any caching solution depends on understanding these trade-offs and crafting strategies that align with your system’s needs. Prioritizing data with high access frequency and low volatility, alongside considerations for data size, helps ensure that limited cache space is used efficiently.
The challenge of maintaining data consistency is equally critical. Cache invalidation requires thoughtful strategies like synchronous updates or time-to-live (TTL), each with its pros and cons. While synchronous updates reduce the window of stale data, they add synchronization overhead. TTL, on the other hand, simplifies cache management but introduces trade-offs between data freshness and system load. Implementing techniques like optimistic locking provides a robust mechanism to handle race conditions and ensure consistency during cache updates, making it a powerful tool for distributed systems.
Ultimately, no caching strategy is one-size-fits-all. Each system has its own unique requirements, shaped by usage patterns, data structure, and operational goals. Successful caching strategies rely on continuous monitoring, testing, and iteration to adapt to changing demands. By carefully balancing performance with consistency, caching can transform system architecture into one that is scalable, reliable, and efficient. Have you faced unique caching challenges or explored innovative solutions? Share your stories—I’d love to hear about your journey in optimizing system performance and architecture!



0 Comments