A reverse proxy is a server that sits between the client and multiple backend application instances. It acts as an intermediary, forwarding client requests to the appropriate application instance while hiding the complexity of the underlying infrastructure. Unlike a typical proxy that sits near the client, a reverse proxy is positioned near the server.
The primary function of a reverse proxy in horizontally scalable systems is to simplify communication between clients and backend instances by providing a single point of entry.
- Without a reverse proxy: Clients must track multiple dynamic IP addresses, which is error-prone and complex.
- With a reverse proxy: Clients only need to know the IP address or domain name of the reverse proxy. The reverse proxy takes care of distributing the requests to the appropriate backend instances.
This greatly reduces complexity and makes the system more manageable, especially when scaling horizontally.
The Role of Reverse Proxy in Horizontally Scalable Systems
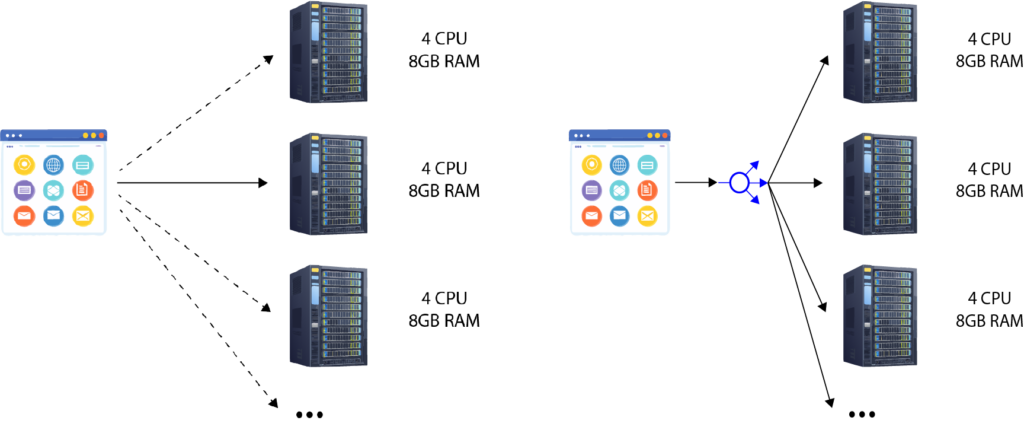
In horizontally scalable systems, where multiple instances of an application run simultaneously to handle increasing loads, a common challenge arises: how can clients reach the right application instance without needing to know every instance’s IP address?
Let’s break this down.
Imagine you have an application that has been scaled horizontally. Instead of a single instance handling all client requests, there are now multiple instances. Any of these instances can process a client request. However, this raises an important question: how does the client know which instance to send its request to?
In a simple setup with one application instance, the client can remember and send requests to the same IP address. But when multiple instances are introduced, the client must be aware of multiple, often dynamically changing IP addresses. As the system scales up or down—adding or removing instances—the number of IP addresses changes constantly.
For clients to track and manage these ever-changing addresses manually would be impractical. This is where the reverse proxy comes into play.
Reverse Proxy as a Load Balancer
In addition to forwarding requests, a reverse proxy often serves as a load balancer, distributing incoming requests evenly across multiple instances. Load balancing is crucial for achieving high availability and preventing individual instances from becoming overwhelmed.
A reverse proxy can implement several load-balancing strategies, such as:
- Round-robin: Requests are distributed in a circular fashion across available instances.
- Least connections: Requests are routed to the instance with the fewest active connections.
- IP hash: Requests are directed based on the client’s IP address, ensuring that subsequent requests from the same client go to the same instance.
By acting as both a reverse proxy and a load balancer, this component not only simplifies client access but also ensures even load distribution, helping the system maintain high throughput and reliability.
Internal vs. External Clients
The role of a reverse proxy becomes even more critical depending on the type of client accessing the application:
- Internal Clients (Service-to-Service Communication)
Internal services accessing the application can use the reverse proxy’s IP address directly. This ensures that internal services do not need to track multiple backend IP addresses and can communicate efficiently. - External Clients (Web Browsers and APIs)
For external clients, such as web browsers, it’s impractical to use raw IP addresses. Instead, the client uses a DNS name to access the application. DNS resolves this name to the reverse proxy’s IP address, providing a seamless experience for external users.
Why DNS Alone is Not Sufficient
While DNS (Domain Name System) is essential for resolving domain names to IP addresses, it cannot replace a reverse proxy for handling dynamically scaling instances. The main reason is DNS caching.
DNS records are often cached at various levels (browser, operating system, and DNS resolver), which can lead to stale information. This caching makes it difficult to update DNS records quickly when instances are added or removed. A reverse proxy, on the other hand, can dynamically adjust to changes in backend instances in real time, ensuring that traffic is always routed correctly.
Thus, for highly scalable and dynamic systems, relying on DNS alone is insufficient. The combination of DNS for name resolution and a reverse proxy for request routing is the optimal solution.
Key Benefits of a Reverse Proxy in Scalable Architectures
- Single Point of Entry: Simplifies client interaction by providing one IP address or domain name.
- Dynamic Load Balancing: Ensures even distribution of traffic across instances for high availability.
- Improved Security: Acts as a security layer, shielding backend instances from direct exposure to the internet.
- Scalability Support: Seamlessly handles scaling up and down without client-side changes.
- Caching and Compression: Enhan
Conclusion
In horizontally scalable systems, a reverse proxy is an indispensable component. It simplifies client communication, supports dynamic scaling, and enables intelligent load balancing. Whether your application is handling a few hundred users or millions, a reverse proxy ensures that requests are routed efficiently and the system remains robust.
In the next post, we’ll dive deeper into load-balancing strategies and explore how to implement reverse proxies using popular tools like NGINX, HAProxy, and AWS Elastic Load Balancer (ELB). Stay tuned to learn how these components work together to build scalable, resilient systems.


0 Comments