It’s crucial to differentiate performance from scalability before diving into how we make a system scalable.
While these terms are related, they serve different purposes in the context of building scalable software architectures.
What is Performance in Software Systems?
Performance is a measure of how efficiently a system responds to requests under a specific load. Two primary metrics help define system performance:
- Latency – The time taken to process a request and deliver a response. Low latency means faster response times, which is essential for a high-performance system.
- Throughput – The number of requests a system can handle per second. High throughput indicates a system’s ability to process a large volume of requests concurrently.
When discussing performance, it’s always about how well a system behaves under a given load. The goal is to minimize latency and maximize throughput by improving two core aspects:
- Concurrency: Enhancing the system’s ability to execute multiple operations simultaneously. Under the performance optimization umbrella, we often focus on single-machine concurrency, typically achieved through multi-threading.
- Capacity Augmentation: Adding resources like CPU, memory, or faster disks to a single machine to improve its ability to handle more requests. This falls under vertical scaling, which we’ll explore in more detail later.
Distributed Processing and Multi-Machine Concurrency
While single-machine concurrency is an essential part of performance improvement, distributed processing takes scalability to another level. Here, we execute the same process across multiple machines to share the load. This is key for building scalable microservices architectures or service-oriented architectures (SOA), where each component can be scaled independently to meet demand.
What is System Scalability
Scalability is a subset of performance, focusing on the system’s ability to maintain or improve its throughput under variable load conditions.
Unlike performance, which assumes a fixed load, scalability deals with increasing and decreasing loads. The ultimate goal is to ensure the system can handle millions—or even tens of millions—of users without a significant drop in performance.
To define it clearly:
Scalability is the ability of a system to increase its throughput by adding more hardware resources while maintaining acceptable performance levels.
In scalability, latency is generally assumed to be optimized. The focus shifts to how we can continuously improve throughput as the load increases by adding more hardware. This leads us to two critical types of scaling strategies:
- Vertical Scaling (Scaling Up)
Vertical scaling involves enhancing the capacity of a single machine by upgrading its hardware—adding more CPU, memory, or storage. This approach is straightforward but has limitations. Eventually, you hit a ceiling where a single machine can no longer handle the load. - Horizontal Scaling (Scaling Out)
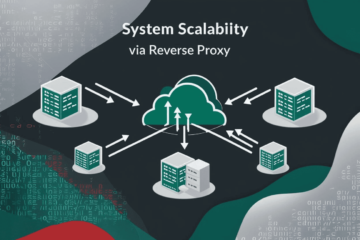
Horizontal scaling adds more machines to distribute the load across multiple instances. This is the backbone of scalable architecture in large systems. By using multiple machines, we can achieve distributed processing, allowing each machine to handle a portion of the requests, thereby increasing overall throughput.
In modern microservices architectures, horizontal scaling is essential. Each service can scale independently based on demand, optimizing resource usage and reducing the risk of a single point of failure.
Scaling Up and Scaling Down: Flexibility in Scalable Systems
In a highly scalable architecture, the ability to scale up and scale down is crucial for maintaining both performance and cost efficiency.
Scalability is not just about adding more resources to handle increasing demand—it’s also about being able to reduce resources during periods of low activity. This balance ensures your system remains responsive without incurring unnecessary operational costs.
Let’s break down these two strategies in detail.
What is Scaling Up (Vertical Scaling)

Scaling up, also known as vertical scaling, involves upgrading a single machine by adding more resources such as CPU, memory, or storage capacity. This approach is typically the first step in improving system performance since it’s easier to implement and doesn’t require significant changes to the system architecture.
Examples of scaling up:
- Adding more CPU cores to handle computation-heavy operations.
- Increasing RAM to improve the performance of memory-intensive applications.
- Upgrading from a standard HDD to an SSD for faster disk I/O operations.
Advantages of Scaling Up:
- Simplicity: No need to modify the application code or architecture.
- Reduced Latency: Vertical scaling often improves latency since it reduces inter-machine communication overhead.
- Good for Monolithic Applications: Works well for traditional monolithic architectures that are harder to scale horizontally.
Disadvantages of Scaling Up:
- Resource Limitations: There’s a physical limit to how much you can scale a single machine. Eventually, you’ll hit the upper bounds of CPU, memory, or storage capacity.
- Downtime Risks: Upgrading hardware often requires temporary downtime, especially in on-premise environments.
- Cost: High-performance hardware can be expensive, especially at the upper end.
What is Scaling Down in Vertical Scaling
Scaling down in a vertical scaling context means downgrading resources when they’re no longer needed—for instance, reducing memory or switching to a less powerful virtual machine in a cloud environment. However, vertical scaling down is less common because hardware downgrades are less flexible than scaling up.
What is Scaling Out (Horizontal Scaling)

Scaling out, also known as horizontal scaling, refers to adding more machines (or instances) to distribute the load across multiple servers. This is the cornerstone of modern scalable systems, especially in microservices or distributed architectures.
Examples of scaling out:
- Deploying multiple instances of an application behind a load balancer.
- Adding database replicas to handle read-heavy operations.
- Partitioning data across multiple nodes in a distributed database like Cassandra or MongoDB.
Advantages of Scaling Out:
- No Single Point of Failure: Distributing the load reduces the risk of a single server becoming a bottleneck.
- Infinite Scalability (Theoretically): Cloud providers offer near-unlimited resources, enabling systems to scale out almost infinitely.
- Cost Flexibility: With cloud platforms, you can pay only for the resources you use, scaling out during high demand and scaling back during low demand.
Disadvantages of Scaling Out:
- Complexity: Requires more sophisticated architecture, including load balancers, distributed databases, and service discovery mechanisms.
- Consistency Challenges: In distributed systems, maintaining data consistency across multiple nodes can be difficult.
- Latency Overhead: Communication between multiple machines may introduce additional latency compared to vertical scaling.
Scaling Down in Horizontal Scaling: Cost Optimization and Flexibility
Scaling down is just as important as scaling up.
In horizontal scaling, scaling down involves reducing the number of active servers or instances when demand decreases. This capability helps minimize costs without sacrificing performance during periods of low activity.
Examples of Scaling Down:
- Reducing the number of application instances in the evenings or on weekends when traffic is low.
- Shutting down non-essential services during maintenance windows.
- Automatically terminating unused virtual machines in a cloud environment.
Cloud platforms like AWS Auto Scaling, Azure Scale Sets, and Google Cloud Instance Groups make it easy to implement automatic scaling policies based on predefined metrics such as CPU utilization, memory usage, or request counts.
Best Practices for Scaling Down:
- Monitor Load and Usage Patterns: Use metrics and monitoring tools (e.g., AWS CloudWatch, Prometheus, or Datadog) to track resource utilization and predict when to scale down.
- Implement Auto-Scaling Policies: Set up rules to automatically scale down resources when usage falls below a certain threshold.
- Stateless Services: Design services to be stateless so they can be easily terminated and restarted without affecting the system’s state.
- Graceful Shutdowns: Ensure services can shut down gracefully, completing current tasks before termination to avoid data loss or errors.
Conclusion
In summary, scalability is not just about handling increased traffic—it’s about ensuring that your system can maintain high throughput and optimal performance as the load fluctuates, whether due to user growth, seasonal spikes, or sudden surges in demand. Scalability is essential for modern software systems, where performance expectations are high, and downtime is costly.
Choosing the right scaling strategy is crucial.
- Vertical scaling (scaling up) is often simpler to implement, as it involves upgrading the existing machine with more powerful hardware. While this can provide quick improvements, it has limitations in terms of cost and a natural ceiling—you can only scale up so far.
- Horizontal scaling (scaling out) offers greater flexibility and long-term growth by adding more machines to your system. This approach, however, requires a more distributed architecture to handle the complexities of managing multiple servers and ensuring that they work seamlessly together.
To achieve effective horizontal scaling, key components such as distributed processing, microservices architecture, and load balancing become essential. These elements help systems distribute the workload, isolate services for easier scaling, and ensure traffic is balanced across available resources, preventing any single point of failure.

0 Comments