Let’s focus on a crucial aspect: HTTP caching for static data. This is the first of a multi-article discussion about caching techniques. Static data, typically served through the HTTP protocol, offers excellent opportunities for optimization.
I’ll draw from personal experiences managing and scaling web applications to give you practical insights. The focus here is on how HTTP caching works, the different servers involved, and the strategies to implement it effectively.
What is Static Data Caching
Static data refers to resources like images, JavaScript, CSS, and other assets that rarely change. Unlike dynamic data, which is generated in real-time or frequently updated, static data benefits immensely from caching. HTTP caching optimizes the delivery of these assets by reducing load times and server overhead.
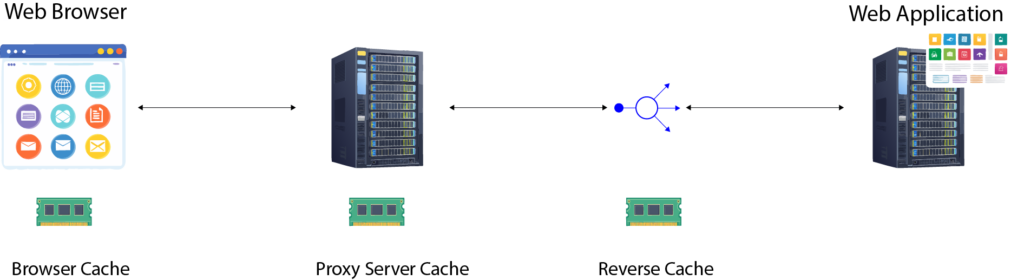
Understanding Caching Layers in HTTP
When a browser requests data from a web application, the request and response pass through several layers. Some of these layers can cache the responses to serve subsequent requests faster. Here are the primary layers where caching happens:
1. Browser Cache (Private Cache)
- Located directly on the user’s device.
- Stores responses for the specific user.
- Ideal for private resources like profile images.
2. Proxy Server Cache (Public Cache)
- A shared cache located closer to the user.
- Consolidates requests from multiple users accessing the same resources.
- Common in office networks or ISPs.
3. Reverse Proxy Cache (Private Cache)
- Sits between the client and multiple backend application instances.
- Typically internal to the system and caches responses close to the origin server.
- Examples include NGINX or Varnish.
Public vs. Private Caches
Understanding the distinction between public and private caches is critical:
- Public Cache: Shared among multiple users. It’s ideal for data like a website’s logo or CSS files that are the same for all users.
- Private Cache: Specific to an individual user. Stores data like session tokens or personalized images.
How HTTP Caching Works
Caching behavior is controlled by HTTP headers. Let’s break down the key headers:
1. Cache-Control Header
The Cache-Control header specifies if and how a resource should be cached. Key directives include:
max-age: Specifies how long the resource can be cached.no-cache: Allows caching but requires validation with the origin server before use.no-store: Prevents caching entirely.public: Indicates the resource is suitable for shared (public) caches.private: Restricts caching to private caches, like browser caches.
2. Expires Header
Specifies an absolute expiration date and time for the cached resource.
3. ETag (Entity Tag)
ETags are unique identifiers for a resource version. If the resource changes, its ETag changes. Clients validate their cached resource by comparing their ETag with the server’s.
Optimizing HTTP Caching with Reverse Proxies
In most modern architectures, reverse proxies like NGINX or Varnish play a crucial role in caching static resources. They can:
- Offload requests from backend servers.
- Serve cached content directly.
- Handle headers for cache control.
NGINX Example:
location /static/ {
root /var/www/static;
expires 7d;
add_header Cache-Control "public";
}
In this example, static files are cached for 7 days, reducing load on the origin server.
How ETags Work in HTTP Caching
ETags provide an additional layer of control. When a client requests a resource, it includes the ETag from its cache:
Workflow:
- The client sends a request with the
If-None-Matchheader containing the cached ETag. - The server compares the ETag with the current resource version.
- If they match, the server responds with a
304 Not Modifiedstatus, saving bandwidth. - If they don’t match, the server sends the updated resource with a new ETag.
Example:
GET /image.jpg HTTP/1.1
If-None-Match: "v1.23.4"
HTTP/1.1 304 Not ModifiedOptimistic Locking with ETags
When managing static resources in an application, ETags can prevent conflicting updates. Here’s how you can implement optimistic locking in both C# and Python.
C# Example:
public class ResourceController
{
private readonly Dictionary<string, string> _etagStore = new();
public string GetResource(string id)
{
// Simulated resource retrieval
string resource = "Resource Content";
string eTag = GenerateETag(resource);
_etagStore[id] = eTag;
return resource;
}
public bool UpdateResource(string id, string newContent, string clientETag)
{
if (!_etagStore.ContainsKey(id)) return false;
string serverETag = _etagStore[id];
if (clientETag != serverETag)
{
throw new InvalidOperationException("ETag mismatch: Resource has been updated by someone else.");
}
_etagStore[id] = GenerateETag(newContent);
return true;
}
private string GenerateETag(string content)
{
using var sha = System.Security.Cryptography.SHA256.Create();
byte[] hash = sha.ComputeHash(System.Text.Encoding.UTF8.GetBytes(content));
return Convert.ToBase64String(hash);
}
}Python Example:
import hashlib
class ResourceManager:
def __init__(self):
self.etag_store = {}
def get_resource(self, resource_id):
resource = "Resource Content"
etag = self._generate_etag(resource)
self.etag_store[resource_id] = etag
return resource, etag
def update_resource(self, resource_id, new_content, client_etag):
server_etag = self.etag_store.get(resource_id)
if not server_etag:
raise KeyError("Resource not found")
if client_etag != server_etag:
raise ValueError("ETag mismatch: Resource has been updated by someone else.")
self.etag_store[resource_id] = self._generate_etag(new_content)
return True
def _generate_etag(self, content):
return hashlib.sha256(content.encode('utf-8')).hexdigest()
# Example Usage
manager = ResourceManager()
resource, etag = manager.get_resource("123")
try:
manager.update_resource("123", "Updated Content", etag)
except ValueError as e:
print(e)Conclusion
Static data caching with HTTP is a cornerstone of performance optimization, offering a powerful way to reduce server load, minimize latency, and improve the overall user experience. Static assets—such as images, CSS, JavaScript files, and pre-rendered HTML—are essential components of modern web applications, and caching them effectively can provide immediate and long-lasting performance benefits.
By understanding the various caching layers—browser caching, reverse proxies, content delivery networks (CDNs), and server-side caching—you can design a caching strategy that ensures content is delivered quickly and reliably to end users. HTTP headers such as Cache-Control, ETag, and Expires give you fine-grained control over how long resources are cached and when they should be refreshed. For example:
Cache-Control: Defines caching policies to specify how and for how long a resource should be cached.ETag: Helps with conditional requests, ensuring that only updated content is fetched, reducing unnecessary data transfer.- Reverse Proxies: Tools like NGINX or Varnish can cache static files and serve them directly, bypassing your application server to enhance performance and scalability.
- CDNs: These distribute static content to servers located near your users, reducing latency and ensuring consistent delivery across geographic regions.
An optimized static caching strategy doesn’t just improve speed—it also frees up server resources, allowing your backend to focus on processing more complex, dynamic requests. This balance leads to greater system reliability and scalability as your application grows.
But caching static data is just the first step in building a truly high-performance architecture. Dynamic data presents a different set of challenges, requiring more sophisticated caching strategies to balance freshness and performance. Cache invalidation, session-specific caching, and distributed caching are essential concepts for managing frequently changing data without sacrificing speed.



0 Comments