When it comes to system performance, the ultimate goals are clear: minimize latency and maximize throughput.
While these objectives might sound straightforward, achieving them in practice is anything but simple. Over the years, I’ve learned that architecting solutions for these goals requires a deep understanding of how systems behave under different workloads, as well as the ability to identify and address bottlenecks effectively.
In this article, we’ll explore what latency and throughput really mean, how they impact system performance, and the strategies I’ve used to optimize them in real-world scenarios. Whether you’re working on a high-traffic web application, a data-intensive backend service, or a batch processing pipeline, these insights will help you design systems that are fast, scalable, and resilient.
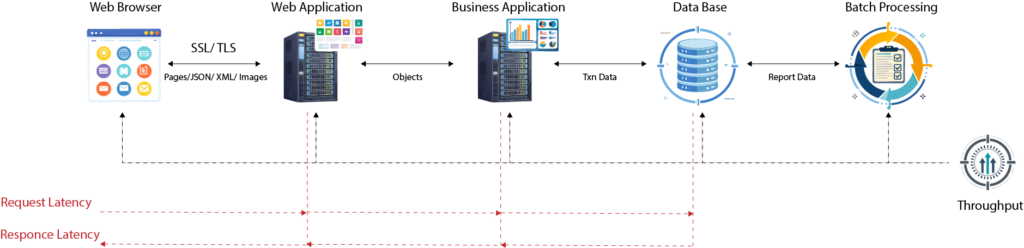
Example Web System
Understanding Latency
Latency is the total time a request spends inside the system, from when it’s received until the response is sent.
It’s a critical metric for any system that requires real-time interaction, such as web applications, APIs, or databases. Latency can be broken down into two main components:
- Processing Time: This is the time spent actively working on the request, such as executing code, running database queries, or performing computations.
- Wait Time: This is the time spent waiting—for example, in a queue or for a shared resource to become available.
The formula for latency is simple:
Latency = Processing Time + Wait Time
In my experience, wait time is often the bigger culprit when it comes to high latency. For instance, on one project, we had a high-traffic API that users complained was too slow. Upon analysis, we discovered that most of the time wasn’t spent processing requests—it was spent waiting in queues due to resource contention. By optimizing resource allocation and reducing these bottlenecks, we were able to significantly improve latency.
The key takeaway here is that minimizing latency requires addressing both processing time and wait time. Efficient code and algorithms can reduce processing time, while strategies like load balancing, caching, and asynchronous processing can help minimize wait time.
Decoding Throughput
Throughput refers to the number of requests a system can handle in a given period. It’s essentially the rate at which the system processes requests.
If latency is how long it takes to serve one customer at a restaurant, throughput is how many customers you can serve in an hour.
Throughput is closely tied to two factors:
- Latency: If individual requests take less time to process, the system can handle more requests overall.
- Capacity: The amount of available resources—such as CPU, memory, disk I/O, and network bandwidth—determines the upper limit of throughput.
I learned this the hard way while scaling a system for peak traffic during a promotional event. Even after optimizing latency, we hit a wall because our servers simply didn’t have enough capacity to handle the volume of requests. By increasing server instances (horizontal scaling), we were able to boost throughput without compromising performance.
The lesson here is that throughput optimization requires a balance between low latency and sufficient capacity. While reducing latency can improve throughput, there’s a limit to how much you can achieve without scaling resources.
The Relationship Between Latency and Throughput
Latency and throughput are interconnected, but capacity plays a crucial mediating role. Here’s how they relate:
- Minimizing Latency: Reducing the time each request spends in the system naturally increases throughput—up to the capacity limit.
- Maximizing Throughput: Requires balancing low latency with enough capacity to handle the workload.
Think of it this way: if your system is a highway, latency is the speed limit, and throughput is the number of cars passing per hour. Adding lanes (capacity) increases throughput, but reducing congestion (latency) ensures traffic flows smoothly.
In practice, this means that optimizing system performance often involves a combination of strategies:
- Reducing Latency: By optimizing code, improving resource utilization, and minimizing bottlenecks.
- Increasing Capacity: By scaling hardware or leveraging cloud-based solutions for elastic scaling.
Request-Response vs. Batch Processing Systems
The type of workload your system handles plays a significant role in determining performance objectives. Broadly, workloads fall into two categories:
- Request-Response Systems:
These systems, such as web applications, APIs, or databases, require quick responses to individual requests. For these systems, both latency and throughput are critical.- Example: On an e-commerce site, customers won’t wait if product pages take too long to load. Reducing latency ensures a smooth user experience while maximizing throughput means the system can handle more users during sales events.
- Batch Processing Systems:
These systems process data in bulk, such as generating reports, transforming datasets, or running analytics jobs. Here, latency is less important since there’s no request-response interaction. Instead, the focus is on throughput—how much data can be processed in a given time—and the total batch processing time.- Example: In a data pipeline I worked on, optimizing throughput meant rethinking how tasks were divided among workers and ensuring no single process became a bottleneck.
Understanding the type of workload your system handles is crucial for setting the right performance objectives and applying the appropriate optimization strategies.
Why Focus on Latency First
In most cases, minimizing latency should be the first priority because:
- Improved User Experience: Lower latency directly translates to faster response times, which enhances user satisfaction.
- Indirect Throughput Gains: Reducing latency often improves throughput, assuming the system has sufficient capacity.
Capacity augmentation, such as scaling servers or adding more resources, is usually straightforward—especially with cloud platforms offering elastic scaling. However, reducing latency requires a deeper understanding of:
- Efficient Code and Algorithms: Ensuring that the logic and computations are optimized for speed.
- Resource Utilization: Making the most of available CPU, memory, and disk resources.
- Bottleneck Elimination: Identifying and addressing queues or contention for shared resources.
For example, on one project, we discovered that a poorly optimized database query was causing significant delays. By optimizing the query with better indexing, we not only reduced latency but also allowed the system to handle more concurrent requests without additional hardware.
Bringing It All Together
Here’s a summary of the key lessons I’ve learned over the years:
- Start with Latency: Focus on identifying and eliminating inefficiencies. This often leads to significant performance improvements with minimal investment in additional resources.
- Balance Throughput and Capacity: Once latency is optimized, ensure the system has enough capacity to meet demand. Monitor and scale as needed to handle growth or traffic spikes.
- Understand the Workload: Tailor your performance goals to the type of system you’re working on—whether it’s a real-time request-response model or a batch processing pipeline.
Final Thoughts
Every system performance exercise I’ve been part of has come down to two objectives: minimize latency and maximize throughput. The journey to achieve them is often iterative, involving deep dives into how systems behave under load, identifying bottlenecks, and applying targeted optimizations. An agile approach—iterating and testing theories—has proven invaluable in this process.
By focusing on these objectives and understanding the interplay between latency, throughput, and capacity, you can build systems that are not only fast and responsive but also scalable and resilient. In the next section, I’ll share practical strategies for measuring and optimizing system performance, drawing from real-world examples to help you achieve these goals.

0 Comments